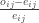Knitr y Rmarkdown.
Publicado el 2016-05-05
ültima actualización: 2016-05-06
Esta entrada es la primera de una serie que quiero dedicar a describir algunas herramientas del ecosistema R que en los últimos tiempos he ido incorporando a mi forma de trabajar. Quiero escribir sobre los siguientes temas, con la intención confesa de estimular la curiosidad de quien pueda leer estas entradas:
- Knitr y Markdown.
- Programación literaria.
- Shiny.
- Reproducible Research.
- El paquete exams de R.
Tiempo habrá, en otras entradas de esa serie, para adentrarse en los detalles y la historia. Lo que quiero hacer hoy es simplemente empezar. Y no hay mejor manera de empezar que con un ejemplo muy sencillo.
Las cosas serán más fáciles si ya eres usuario de RStudio. Si no lo eres: (a) te lo recomendamos una vez más y (b) puedes encontrar algo más de información e instrucciones de instalación en nuestro Tutorial00 (pdf). Primero explicaremos como proceder en RStudio, y luego daremos algunas indicaciones para quienes no lo usen.
Usando RStudio para crear un documento Rmarkdown.
En RStudio empieza por ir al menú Tools y dentro de ese menú selecciona Global Options. Se abrirá una ventana de opciones como esta:

En la que, como hemos indicado, debes seleccionar Sweave (más adelante, en otra entrada, hablaremos más de Sweave). Al hacerlo aparecerán las opciones de la siguiente figura:

Y como muestra la flecha debes asgurarte de que has seleccionado Knitr bajo la opción Weave Rnw files using. Puedes dejar el resto de las opciones como están por el momento. Haz click en Ok.
Ya estamos casi listos. Ahora, usando el menú File de RStudio, selecciona la entrada New File y, dentro de esta, elige R Markdown. Aparecerá esta ventana:

Elige un título para el documento, añade la información de autoría y pulsa en Ok. Yo he elegido como título Comenzando con Rmarkdown. ¡Pero cuidado! El título que has elegido es sólo eso: un título (en particular puede contener espacios, acentos, etc). Tu documento todavía no está guardado en disco. Enseguida lo guardaremos. Pero antes fíjate en que en la ventana del Editor de RStudio ha aparecido un documento con un texto inicial. Más abajo vamos a analizar la estructura de ese texto.

Pero si te fijas verás que el documento sigue siendo Untitled, inidcando que aún no lo hemos guardado. Hazlo ahora, usando el menú File/Save as y guarda el documento en una carpeta adecuada. Tendrás que elegir el nombre del fichero, que no tiene porque tener nada en común con el título que has elegido antes. Eso sí, como de costumbre, te recomiendo que no uses espacios, acentos o caracteres especiales en el nombre del fichero. No te preocupes por la extensión: RStudio añadirá de forma automática la extensión Rmd al fichero. Yo he elegido como nombre testRmarkdown01.
¿Ya lo has guardado? Estupendo. Pues ahora, antes de hacer nada más, vamos a ver hacia dónde nos encaminamos: pulsa el botón Knit HTML que aparece sobre el editor de RStudio, y que puedes ver en la siguiente figura:
Tras pulsarlo verás que, en el espacio que normalmente ocupa la consola de RStudio aparece fugazmente una nueva pestaña titulada R markdown que muestra mensajes con información sobre el proceso que RStudio está llevando a cabo con nuestro documento. Y digo fugazmente porque, con un documento tan breve, en apenas unos instantes verás aparecer una nueva ventana, el visor de RStudio, que muestra el resultado que hemos obtenido al procesar ese documento.

Por si tienes algún problema, este enlace muestra el resultado que deberías obtener.
¿Y si no uso RStudio?
En ese caso puedes descargarte el fichero de código para Knitr desde este enlace:
testRmarkdown01.Rmd
Guárdalo en tu directorio de trabajo con R y ábrelo con el editor de texto que uses habitualmente con ficheros de código R.
Para procesarlo (el equivalente del botón Knit de RStudio), ejecuta este código en la consola de R:
rmarkdown::render("testRmarkdown01.Rmd")Al hacerlo, en tu directorio de trababjo aparecerá un fichero llamado testRmarkdown01.html. Ábrelo con tu navegador de internet para ver el resultado que ha producido Knitr. Debería ser parecido a este.
En lo que resta de esta entrada, cada vez que yo diga que hay que pulsar el botón Knit de RStudio, tú deberás ejecutar de nuevo esa instrucción para volver a generar el documento HTML.
El documento HTML producido por Knitr.
El documento que estás viendo es un documento HTML, como los que se usan en las páginas Web. Es un documento con un formato visual simple, pero que contiene elementos visuales como texto en cursiva, negrita, títulos con dierente tamaño de letra. Además, se incluyen enlaces reconocibles, como en cualquier página web. Pero, como puedes ver, lo más interesante es que en ese documento aparecen recuadros sombreados con código R y a continuación el resultado de la ejecución de ese código. El primero de esos bloques usa la función summary con el conjunto de datos cars y el resultado aparece justo debajo. Además aparece un gráfico, también realizado con R, aunque en este caso el código que se ha usado para fabricar el gráfico es invisible. De hecho, la última frase del documento hace referencia a esto y explica de forma sucinta cómo se ha conseguido.
Hay muchas cosas ocurriendo a la vez en esta ventana, ya lo sé. Pero tendremos ocasión de ir desgranando poco a poco los detalles técnicos. lo más importante en este momento del proceso es captar la idea general: tenemos un documento inicial (el fichero testRmarkdown01.Rmd) y RStudio lo ha procesado (usando Knitr) para dar como resultado esta página web que contiene código R y los resultados que produce ese mismo código. Como pronto verás, esas páginas web son un documento extremadamente flexible que nos va a permitir crear documentos muy sofisticados de forma muy productiva. No sólo eso, sino que al tratarse de documentos de texto muy sencillos, podemos escribir programas en R que se encarguen de crear y publicar de manera automática esas páginas web cuando, por ejemplo, los datos que nos interesan hayan cambiado.
Estructura del documento en Rmarkdown.
El documento testRmarkdown01.Rmd es nuestro primer ejemplo de documento Rmarkdown. Vamos a analizar la forma en la que está construido. A grandes rasgos el documento contiene tres tipos de elementos:
La cabecera.
Que aparece justo al principio del documento, comprendida entre las dos líneas que contienen ---. Ese bloque de cabecera es, en este documento de muestra:
title: "Comenzando con RMarkdown."
author: "www.postdata-statistics.com"
date: "4 de mayo de 2016"
output: "html_document"Este bloque está escrito en su propio lenguaje, denominado YAML. Pero no te preocupes demasiado. Por el momento todo lo que necesitamos saber es esto:
- La función de esas líneas es evidente. Aquí se determina el título, autor, fecha y, en la última línea, cuál es el tipo de documento que queremos producir. En este caso HTML para producir un documento para la web. Pero más adelante veremos cómo producir, por ejemplo, un pdf o un documento docx para Microsoft Word.
- Además, este bloque es opcional. Si borras todo el bloque entre las dos líneas con
---(incluidas esas líneas), Knitr seguirá siendo capaz de procesar el documento resultante. - Si sabes algo sobre creación de documentos HTML es posible que el ejemplo anterior te haya parecido muy básico. Es cierto. Pero cuando aprendamos un poco más, podremos usar este bloque YAML de la cabecera para incluir, por ejemplo, nuestras propias hojas de estilo CSS. Se pueden llegar a hacer cosas bastante sofisticadas.
Texto en markdown.
Además, el documento contiene párrafos de texto escritos en markdown. El lenguaje markdown sirve para representar el formato de un documento de una forma muy sencilla. A menudo se dice que la sintaxis básica de markdown se aprende en un minuto. Por ejemplo, para escribir un texto en negrita basta con rodearlo con dos asteriscos a cada lado. En el documento testRmarkdown01.Rmd tienes un ejemplo. El segundo párrafo contiene esta frase:
When you click the **Knit** button a document will be generated ... Como ves, la palabra Knit aparece con dos asteriscos a cada lado. Al procesar el documento con Knitr, el resultado es que la palabra Knitr aparece en negrita, como puedes ver en esta figura:

También puedes ver, en el primer párrafo de texto, lo fácil que resulta insertar un enlace a una página web. Basta con escribir
<http://rmarkdown.rstudio.com>para crear ese enlace. Si quisieras hacer lo mismo usando HTML tendrías que escribir:
<a href="http://rmarkdown.rstudio.com">http://rmarkdown.rstudio.com</a>Como ves, bastante más complicado. Esa simplificación es la clave que convierte a markdown en una herramienta extremadamente productiva. Porque puede sonar a exageración, pero te aseguro que el tiempo que dediques a aprender a usar markdown será una de las inversiones más rentables que puedes hacer en términos de productividad. Un buen ejemplo puede ser esta página:
http://www.markitdown.net/markdown
en la que puedes ver a la izquierda ejemplos de código markdown y a la derecha su traducción cuando se convierten en HTML para producir una página web. Además ese documento tiene la ventaja de que proporciona una demostración interactiva del funcionamiento de markdown. Haz un cambio a la izquierda y verás su efecto a la derecha. Es muy conveniente que dediques algún tiempo a hacer experimentos allí para familiarizarte con los ingredientes básicos del markdown. Tal vez no sea un minuto, pero tampoco vas a necesitar una hora, desde luego. A cambio, después podrás usar markdown en la creciente colección de sitios web y programas compatibles con su uso: WordPress, GitHub, los foros de StackOverflow y sus asociados, etc. Usar markdown no es la panacea universal, pero para muchos de nosotros se ha convertido en una de esas herramientas que te llevan a preguntarte cómo podías pasarte sin ellas antes.
Bloques de código R.
Pero hemos dejado para el final lo mejor. El documento contiene además bloques de codigo R (en inglés se habla de R code chunks). Por ejemplo, el primero de esos bloques es muy breve, y sólo contiene una llamada a una función de R:
summary(cars)La siguiente figura muestra la manera de indicarle a Knitr los límites de uno de esos bloques de código:

Cuando Knitr procesa el fichero testRmarkdown01.Rmd va buscando estos bloques de código y los ejecuta secuencialmente, uno tras otro. Y a medida que los ejecuta va insertando las respuestas de R en el documento html que produce, dentro de unos bloques de resultados que aparecen recuadrados (ahora con fondo blanco) bajo el correspondiente bloque de código.

Prueba a ejecutar summary(cars) en tu consola de R y verás que obtienes el mismo resultado web que aparece en el documento elaborado por Knitr.
Un inciso sobre Programación Literaria.
Este ejemplo es tan sencillo que puede que no resulte obvio lo que acabamos de explicar. Por eso voy a insistir en el punto clave. Tradicionalmente, ejecutaríamos ese código en R y entonces copiaríamos y pegaríamos el resultado en algún documento, informe, página web, etc. Esa es la forma tradicional de incorporar los resultados de la ejecución del código a las publicaciones científicas o los informes técnicos. En particular, el código y nuestras explicaciones o argumentos basados en ese código vivirían en ficheros separados. Por supuesto, si el código cambia, es muy posible que esas explicaciones y argumentos ya no sean válidos, con lo que las ocasiones para el error aumentan. Pero con Knitr eso ya no es necesario: el código y el texto van unidos en un mismo documento. Esa es una de las ideas centrales de la Programación Literaria, de la que hablaremos más extensamente en alguna otra entrada.
Figuras y control del código que se muestra.
El segundo bloque de código R que aparece en testRmarkdown01.Rmd es también interesante, porque ilustra:
- la forma de obtener un gráfico.
- cómo podemos controlar qué partes del código R se muestran y cuáles se ocultan.
Ese bloque es:

Fíjate en que para obtener la figura simplemente hemos incluido la función plot de R que produce esa figura. Insisto otra vez en lo que no hemos hecho: no hemos fabricado la figura con R para después hacer un corta/pega. Si fuera así y más adelante cambiamos algo en nuestro código, la figura ya no se correspondería con el código y habría que volver a pasar por el ciclo completo de generar la figura correcta, copiarla y pegarla. Pero si la figura se genera e inserta automáticamente a partir del código… ¿te das cuenta del avance que supone esta forma de trabajar?
Enseguida vamos a ver otro ejemplo para abundar en esas ideas. Pero antes vamos con el segundo punto que ilustra este segundo bloque de código del ejemplo. Si vuelves a mirar el documento html que ha producido Knitr, verás que el código plot(cars) no aparece por ningún lado (a diferencia de lo que ocurría con summary(cars), que sí era visible en el documento final). Para hacer invisible ese código, la cabecera del segudo bloque de código incluye la instrucción echo = FALSE de Knitr. Hagamos un experimento. Cambia echo = FALSEpor echo = TRUE y vuelve a pulsar el botón Knit de RStudio.

Ahora, además de la figura, puedes ver el código que la produce en el documento final. Además de echo, hay muchas otras opciones que podemos introducir en la cabecera de un bloque de código para controlar el comportamiento de Knitr. Por ejemplo, con eval=TRUE o eval=FALSE puedes decidir si un bloque de código se ejecuta o no. ¿Y si no quiero que un bloque se ejecute, no es más fácil no incluirlo o comentarlo? Puede parecer que sí, a primera vista. Pero ¿y si tedigo que puedes usar algo como eval=x, donde x es una variable booleana de R y que por lo tanto puedes decidir programáticamente qué partes del código se ejecutan y cuáles no? Es decir, que si algo cambia en tus datos y ya no quieres mostrar un cierto tipo de gráfico, puedes usar eval y echo para encender/apagar partes de tu documento. Y no hemos hecho más que rozar la superficie. Las posibilidades con Knitr son inmensas.
Un ejemplo más.
Vamos a añadir algunos ingredientes más al fichero testRmarkdown01.Rmd para ilustrar las ideas anteriores. Para empezar, añade estas líneas al final del documento (exactamente como aparecen aquí, puedes copiarlas y pegarlas):
## Un ejemplo adicional de gráfica con Knitr.
Vamos a mostrar una gráfica que podremos cambiar **simplemente**
cambiando el valor de la variable `n`.De momento se trata simplemente de un poco más de markdown, sin código R. Cuando hayas añadido esas líneas pulsa de nuevo el botón Knit para ver el resultado. La siguiente figura muestra los cambios que deberías ver en la parte final del documento html procesado.

Vamos con un bloque de código. El código es este:
```{r }
n = 1
x = 1:100
plot(x, x^n, type="l", lwd=4, col="red")
```De nuevo, puedes copiarlo y pegarlo al final del documento. Tras hacer esto pulsa una vez más Knit. EL resultado debería ser cómo el de la siguiente figura:

Como ves, Knitr ha procesado el código y ha incorporado al documento la figura que se obtiene, que con n = 1 es una recta. Para insistir en la idea central de Knitr, cambia ahora ese valor por n = 2 y vuelve a pulsar Knit. Sin necesidad de ningún cambio adicional por tu parte, sólo con cambiar ese número, el resultado será el de la siguiente figura.

Como puedes ver, ahora con n=2 el gráfico es una parábola. Y déjame que insista, a riesgo de ser pesado: no hemos tenido que hacer nada más que cambiar ese número para que todo se actualice en el documento final.
Comentarios finales y enlaces recomendados.
Esta entrada sólo pretende presentar Knitr (y markdown) a quienes no los conozcan todavía y, con suerte, animaros a continuar indagando. En próximas entradas profundizaremos un poco más en el funcionamiento de Knitr. Pero para quien quiera empezar ya, hay dos enlaces que le pueden servir de puerta de entrada.
- La gente de RStudio ha publicado una página de introducción a la combinación de markdown y knitr que denominan Rmarkdown:
http://rmarkdown.rstudio.com/
Recomiendo encarecidamente el Quick Tour y la R Markdown Cheat Sheet. - La página oficial de Knitr, que sirve de carta de presentación a su creador Yihui Xie, es http://yihui.name/knitr/. En ella encontraréis además un enlace al libro de Knitr, que os recomiendo si queréis profundizar en esta herramienta.
Ambos en inglés, me temo. No me convencen demasiado las (escasas) presentaciones de Knitr que he encontrado en español. Aunque, naturalmente, me encantaría que hubiera alguna mucho mejor (me ahorraría el trabajo de escribir estas entradas) y estoy abierto a cualquier sugerencia que los lectores quieran hacerme llegar.
Muchas gracias por la atención.

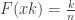




 , los tipificamos, después los usamos para definir una función de distribución empírica, y finalmente la superponemos sobre esta teórica? Para hacerlo, basta con ejecutar este código:
, los tipificamos, después los usamos para definir una función de distribución empírica, y finalmente la superponemos sobre esta teórica? Para hacerlo, basta con ejecutar este código:

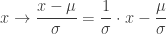
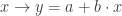



 ,
,  ,…,
,…,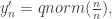

 .
. se parecen mucho a los
se parecen mucho a los  frente a los
frente a los 




 que estamos usando consiste, para este ejemplo, en calcular el siguiente estadístico:
que estamos usando consiste, para este ejemplo, en calcular el siguiente estadístico: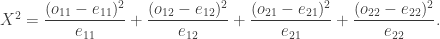
 son los de la tabla observada, y los
son los de la tabla observada, y los 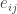 son los valores esperados. Cada término de la forma
son los valores esperados. Cada término de la forma